
Event-Driven Architecture กับราคาที่แอบซ่อน: บทเรียนเลือดเหลวจากระบบ Contact Center 80,000 สายต่อชั่วโมง และ Redis Patterns ที่ช่วยได้จริง
ความตึงเครียดพื้นฐาน: Async โดยธรรมชาติ แต่ Real-Time คือข้อเรียกร้อง
Event-Driven Architecture ได้รับการยกย่องในฐานะแนวทางมาตรฐานสำหรับการสร้าง Distributed System ที่ขยายตัวได้ — loose coupling, independent scalability, fault isolation และความสามารถในการรับมือ throughput สูงโดยไม่ต้องพึ่งพา synchronous dependency เหล่านั้นดูเหมือนจะเป็นสูตรสำเร็จสำหรับทุกระบบจนกระทั่งคุณพบว่ามันไม่ได้ใช่เสมอไป
ลองจินตนาการ Contact Center Platform ที่รับมือมากกว่า 80,000 Busy Hour Call Completions (BHCC) ผ่าน 10,000 Concurrent Agents โดยประมวลผลมากกว่า 5 ล้าน Daily Transactions — ทั้งหมดทำงานบน Apache Kafka เป็น Messaging Backbone หลัก เมื่อ Agent รับสายเข้า UI ต้องสะท้อนสถานะภายในไม่กี่มิลลิวินาที ไม่ใช่ไม่กี่วินาที เมื่อ Supervisor เปิด Team Dashboard ข้อมูล Presence ที่ล้าสมัยไม่ใช่เรื่องเล็กน้อย แต่มันส่งผลต่อ Workforce Management Decision แบบ Real-Time
ผลลัพธ์ที่พบในระบบจริงคือ Agents ที่กดออกสายต้องรอ UI Lag 2-3 วินาทีก่อนหน้าจอจะแสดง Call State ใหม่ ภายใต้ Peak Load บางครั้ง Inbound Call Answer Events ไม่ทัน Propagate ก่อน Timeout ที่ Source จะทำงาน ระบบทำงานถูกต้องตามหลักการ — Events ถูกประมวลผลทั้งหมด — แต่ Async Pipeline ละเมิด Real-Time Contract ที่ผลิตภัณฑ์ต้องการ
นี่คือบทเรียนสำคัญแรก: Event-Driven Architecture เหมาะสมที่สุดเมื่อ Eventual Consistency เป็นที่ยอมรับได้ แต่ในระบบ Communication แบบ Real-Time มี Critical Paths — เช่น Call Signaling, Agent State Transitions และ Presence Updates — ที่ Eventual Consistency ในทางปฏิบัตินั้นทำงานได้เทียบเท่ากับการล้มเหลว บน Critical Paths เหล่านี้ สิ่งที่จำเป็นคือ Synchronous หรือ Near-Synchronous Communication ไม่ใช่ Async Event Pipeline
สำหรับทีม Solution Architects ที่กำลังคิดจะออกแบบเว็บไซต์หรือระบบหลังบ้านขนาดใหญ่ที่ต้องรับมือ Real-Time Workload ความเข้าใจเชิงลึกเกี่ยวกับ Tradeoff นี้ไม่ใช่เรื่อง Nice-to-Have แต่เป็นสิ่งที่ตัดสินว่าระบบจะทำงานใน Production ได้หรือไม่ ในบริษัท คัสโตมิกซ์ จำกัด (Customix) ซึ่งเป็น Software House ที่ได้รับรองมาตรฐาน ISO/IEC 29110 และมีประสบการณ์พัฒนาระบบกว่า 6 ปีด้วย Tech Stack ทันสมัยอย่าง Next.js, Node.js, Redis และ Jenkins เราพบว่าการเลือก Architecture Pattern ที่เหมาะสมกับลักษณะ Workload นั้นมีความสำคัญพอๆ กับการเลือก Tech Stack เอง
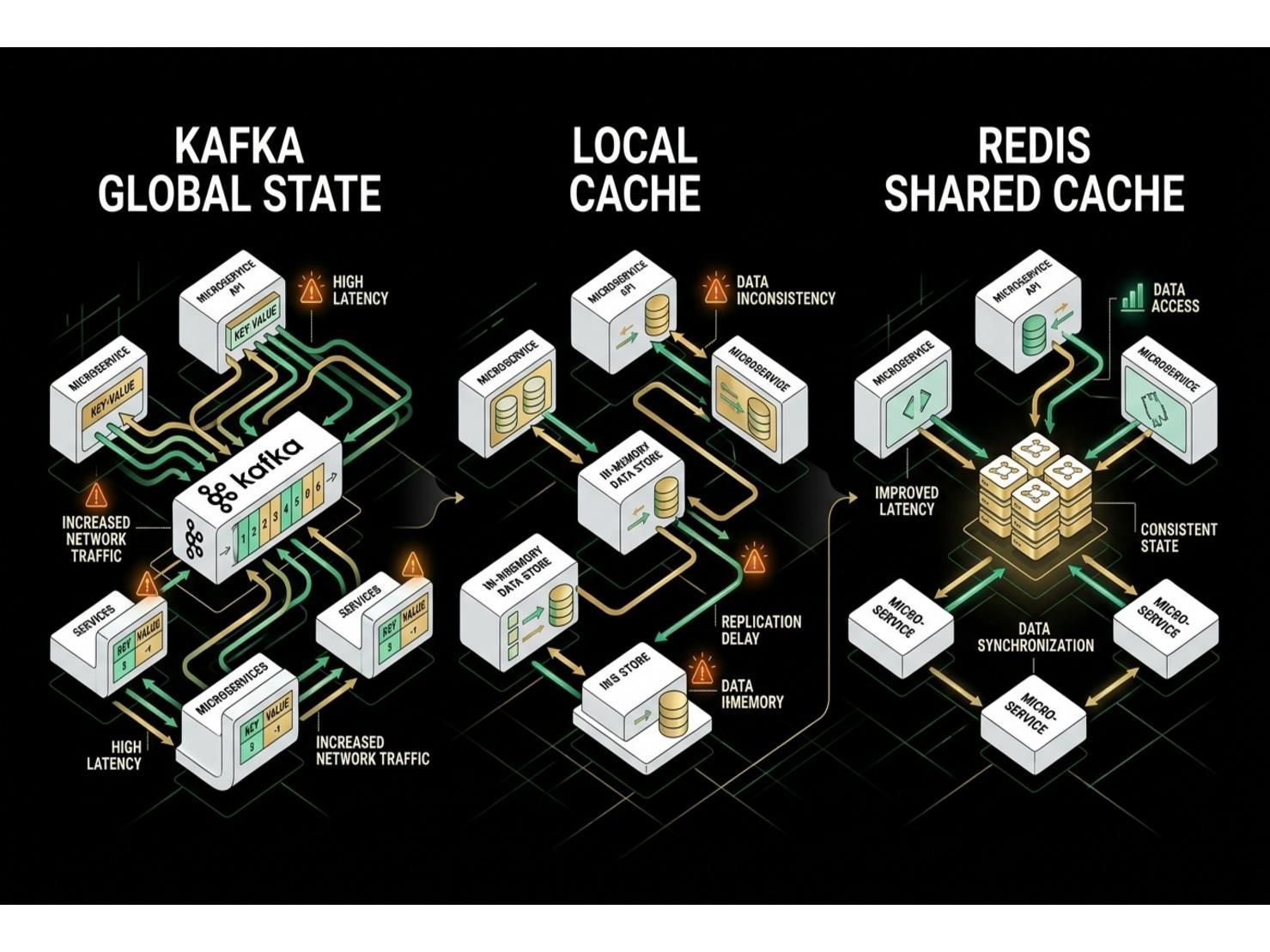
3 Generation ของ State Management: จาก Kafka Global State สู่ Redis Shared Cache ที่เปลี่ยนเกม

หนึ่งในประโยชน์หลักของ Event-Driven Architecture คือการที่แต่ละ Service บำรุง Local State ของตัวเองจาก Event Stream โดยไม่ต้องพึ่งพา Shared Database — แต่ในระบบ Real-Time Collaboration แนวคิดนี้สร้างปัญหาที่ละเอียดอ่อนและอันตราย: Cache Mismatch ระหว่าง Service Instances
เส้นทางการพัฒนา State Management ในระบบนี้ผ่านการ Evolution 3 Generation ซึ่งแต่ละรุ่นแก้ปัญหาของรุ่นก่อนหน้าแต่ก็นำปัญหาใหม่มาด้วย — และนี่คือสิ่งที่ Architecture Diagram ไม่เคยแสดงให้เห็น
Generation 1: Kafka Global State Stores — ทุก Pod ได้รับสำเนาข้อมูลสถานะแบบเต็มผ่าน Kafka Streams Global State Stores ดูเหมือนจะเหมาะสมที่สุดจนกระทั่งคุณพบว่า Synchronization Latency ทำให้ Pod A และ Pod B ถือเวอร์ชัน State ต่างกันของ Agent เดียวกัน Routing Decision จาก Pod A ขัดแย้งกับ Pod B ในเวลาต่อมา — User State และ Call State กลายเป็น Transient Inconsistency ที่ตรวจจับได้ยากและเกือบจะทดสอบซ้ำไม่ได้ใน Testing Environment
Generation 2: Local In-Memory Cache via Kafka Replay — แก้ปัญหา Sync Latency โดยให้แต่ละ Pod สร้าง Local Cache จาก Kafka Event Stream เอง แต่คราวนี้ Startup Latency กลายเป็นปัญหา: Pod ต้อง Replay ทั้ง Event Backlog ใช้เวลาประมาณ 5 นาที ทำให้ Kubernetes Horizontal Pod Autoscaler (HPA) ไม่สามารถทำงานได้ เพราะ Pod ใหม่ที่ HPA สร้างขึ้นจะไม่พร้อมใช้งานเป็นเวลา 5 นาที ในขณะที่ Load Spikes กำลังเพิ่มขึ้น และใน Edge Conditions เช่น Network Partitions, Consumer Lag และ Partial Restarts ทำให้ Pod Instances แตกต่างกัน — Work Cards ติดค้างบน Agent UI นานกว่า 24 ชั่วโมง และ Silent Incorrectness ที่มองไม่เห็นจาก Standard Monitoring
Generation 3: Redis Shared Cache with Resilience Layer — Architecture สุดท้ายที่เปลี่ยนเกมโดยสิ้นเชิง: Kafka Events อัปเดต Redis ทุก Pod อ่านจาก Redis โดยตรง Startup Delay ลดลง 60% เพราะ Pod เริ่มต้นจาก Redis Snapshot แทนที่จะ Replay ทั้ง Kafka Event History แต่การพึ่งพา Redis บน Critical Path จำเป็นต้องมี Resilience Strategy ดังนั้นจึงมี Silent Recovery Thread ที่ทำงานเบื้องหลัง — เมื่อ Pod เริ่มต้นหาก Redis ไม่พร้อม Background Thread จะสร้าง Redis Cache จาก Kafka Event Stream โดยไม่ Block Pod จากการ Serve Traffic Pod จะเริ่มทำงานด้วย Degraded State และค่อยๆ ปรับปรุงตัวเองในขณะที่ Recovery Thread เติมข้อมูลเข้า Redis
State Management ใน Event-Driven System ไม่ใช่ Solved Problem แต่เป็นชุดของ Tradeoffs ที่จะปรากฏตัวเฉพาะภายใต้ Production Load เท่านั้น สิ่งที่ทีมหน้างานควรออกแบบตั้งแต่แรกคือ: ใช้ Redis เป็น Shared Authoritative State, Snapshot Initialization สำหรับ Startup Speed และ Background Recovery Thread สำหรับ Resilience — อย่าปล่อยให้แต่ละ Production Incident เป็นครูสอนทีละเรื่อง เพราะแต่ละครั้งนั้นมีราคาแพงกว่าการออกแบบให้ถูกต้องตั้งแต่ต้น
ที่ Customix เราได้นำประสบการณ์เชิงลึกในการจัดการ State Management และ Distributed Cache ด้วย Redis มาประยุกต์ใช้กับการออกแบบเว็บไซต์และพัฒนาระบบหลังบ้านให้กับลูกค้าหลากหลายรูปแบบ — ทั้งในโครงการ E-commerce ร่วมกับ Computerlogy, การดูแลเว็บไซต์ให้ Loptel และ Baovibe โดยทีมงานผู้เชี่ยวชาญที่มีประสบการณ์กว่า 5 ปี พร้อมดูแลระบบอย่างต่อเนื่องหลังขึ้นใช้งานจริง รวมถึงติดตั้ง Google Analytics เพื่อ Monitor สมรรถนะของระบบอย่างครบวงจร
Cascading Failure: เมื่อ REST Call เดียวแปดเปียวทำให้ทั้ง Pipeline หยุดชะงัก 30 นาที
Production Incident รุนแรงที่สุดที่เกิดขึ้นไม่ได้เกิดจากความล้มเหลวครั้งเดียว แต่เป็น Cascade Effect ที่เริ่มต้นจาก REST API Call ที่ช้าเพียงอันเดียวแล้ว Propagate กลับไปทั่ว Pipeline ทั้งหมด
เหตุการณ์เกิดขึ้นใน Bulk Agent Provisioning — Administrator จัดการ Provisioning 10,000 Agents จาก Admin UI ซึ่ง Publish Events ไปยัง Kafka Topic ที่มีเพียง 3 Partitions ด้วย Kafka Streams ที่ใช้ 2 Threads ต่อ Partition จึงมี Maximum 6 Threads เท่านั้นที่ประมวลผล 10,000 Events และที่สำคัญที่สุด: แต่ละ Consumer Thread ทำ Synchronous Blocking REST Call ไปยัง Downstream Service เมื่อ REST API เสื่อมโทรมภายใต้ Load ทั้ง 6 Threads นั้น Block — และยังคง Block อยู่
Failure Chain นี้มี 4 ปัญหาที่ Compound กันในเวลาเดียวกัน: แรก 3 Partitions กับ 6 Threads ประมวลผล 10,000 Events นั้นมีน้อยเกินไป ประการที่สอง Consumer Thread Block ทำให้ Kafka Message Consumption หยุดชะงักทั้งหมด ประการที่สาม Pipeline ต้องการ 3 Events แยกต่างหากต่อ Agent (Agent, UserFeature, VoiceAgent) เพื่อ Join เป็น UserAggregate ทำให้ 30,000 Messages ไหลผ่าน Bottleneck ของ 3 Partitions และประการที่สี่ Shared Consumer Group ทำให้ Source Event Lag และ Aggregate Event Lag ซ้อนทับกัน
Consumer Lag สูงเกิน 30 นาที Admin UI Timeout ทำงาน Bulk Provisioning ล้มเหลว แต่ไม่ใช่ Failure ที่สะอาด — บาง Agent ถูก Provision แล้วบน Client Side ในขณะที่บาง Agent ยังไม่ได้ ระบบอยู่ในสถานะ Inconsistent โดยไม่มี Automatic Reconciliation ทีม Recovery ต้องใช้เวลา 3 ชั่วโมงในการ Cross-Reference และ Re-trigger ด้วย Idempotency Checks
ทางแก้ไขที่ใช้ได้ผลจริง: รวม 3 Provisioning Events เป็น Unified Event เดียวลด Message Volume ลง 66% และลบ Join Topic ออกไปเลย จากนั้นแทนที่ Synchronous REST Call ด้วย Redis Queue — Consumer Threads เขียน Provisioning Requests ลง Redis และ Return ทันที Worker Pool แยกตัวออกมาประมวลผล REST Calls แบบ Asynchronous Consumer Threads ไม่เคยถูก Block โดย Downstream Latency อีกต่อไป Consumer Lag ลดลง 50% และ Provisioning Operations กลายเป็น Restart-Safe ผ่าน Redis Queue Durability
Principle ที่ได้จากเหตุการณ์นี้: Consumer Thread คือทรัพยากรที่ศักดิ์สิทธิ์ — หน้าที่เดียวของมันคือ Consume และ Hand Off เท่านั้น ห้าม Block ด้วย External Call ใดๆ ทุก Consumer Thread ที่ต้องเรียก External Service ควรทำแบบ Asynchronous โดยเขียนลง Durable Queue แล้ว Return ทันที ทีม Developers หรือ Solution Architects ที่เข้าใจหลักการนี้จะสามารถปกป้องระบบจาก Cascading Failure ที่ซ่อนอยู่ใน Architecture ที่ดูเรียบร้อยบนกระดาษ และผลกระทบจากประสบการณ์เชิงลึกนี้จะสะท้อนกลับไปสู่ Decision Making ระดับองค์กรเมื่อถึงเวลากำหนด Architecture Standard และ Best Practices ของบริษัทใหม่
5 การตัดสินใจทางสถาปัตยกรรมที่ทีมหน้างานควรทำต่างไปจากวันแรก
![Midjourney Prompt: A visionary closing image — a team of developers and solution architects standing around a holographic architecture blueprint that shows hybrid synchronous-asynchronous patterns with glowing green Redis nodes and steady blue WebSocket streams connecting to user interfaces, the scene suggests empowerment and forward-thinking engineering culture, soft ambient lighting with tech-blue and warm gold tones, modern office environment with glass walls showing server racks in background, inspirational and professional atmosphere, 8k resolution --ar 16:9 [🌟 พิกัดภาพปิดท้าย]](https://cms.dev.customix.co/uploads/content4_1782978700245_a1cd20e44a.jpg)
สิ่งที่น่าสนใจที่สุดจากกรณีศึกษานี้ไม่ใช่ปัญหาใดปัญหาหนึ่งโดดๆ แต่คือวิธีการที่ทีมปฏิบัติการหน้างาน — Developers, Architects และ Engineers ที่เผชิญกับ Production Incidents จริงๆ — ค่อยๆ สร้างความรู้สึกที่ลึกซึ้งและหยั่งถึง จนสามารถทบทวนกลับไปและระบุ 5 การตัดสินใจทางสถาปัตยกรรมที่หากทำได้ตั้งแต่แรกจะเปลี่ยนเส้นทางของทั้งโปรเจกต์ไปเลย
ประการแรก: ใช้ Synchronous Paths สำหรับ Latency-Sensitive Operations — Call Signaling, Agent State Transitions และ UI Notifications ควรใช้ WebSocket หรือ gRPC Streams แทน Kafka จงสงวน Kafka ไว้สำหรับ Durable Non-Latency-Sensitive Flows เช่น Analytics, Audit Logs และ CRM Synchronization
ประการที่สอง: ใช้ Redis Shared Cache พร้อม Resilience ตั้งแต่ Day One — ไม่ต้องผ่าน 3 Generation ของ State Management แต่เริ่มจาก Redis เป็น Authoritative Real-Time State Store พร้อม Snapshot Initialization สำหรับ Fast Startup และ Background Recovery Thread สำหรับ Redis Outage Resilience ทั้ง 3 องค์ประกอบนี้จำเป็นต้องมีพร้อมกัน หากมีเพียง 1-2 อย่างจะสร้าง Failure Mode ใหม่ให้คุณ
ประการที่สาม: ใช้ Snapshot-First Initialization — ทุก Service ที่ต้องการ Local State ควร Initialize จาก Snapshot ไม่ใช่จาก Full Event Replay ออกแบบ Snapshot Mechanism ก่อน Deploy ไป Production เพราะ Retrofitting จะยุ่งยากกว่าการสร้างมาตั้งแต่ต้นหลายเท่า
ประการที่สี่: ใช้ Redis-First Deduplication สำหรับ Cross-Cluster Fan-Out — ทุก Architecture ที่มีหลาย Pods รับ Message เดียวกันพร้อมกัน ควรใช้ Redis First-Write-Wins ตั้งแต่แรก เพราะ Kafka-Based Deduplication จะเพิ่ม Unavoidable Polling Latency ทุก Hop โดยเฉพาะกับ Cross-Cluster gRPC Fan-Out ที่ใช้เวลาเพิ่มขั้นต่ำ 200ms ต่อ Hop ซึ่ง Redis Pattern ช่วยลดเหลือ Near-Zero ได้จริง
ประการที่ห้า: ห้าม Block Consumer Threads — เป็นหลักการสูงสุดที่ต้องถือมั่น Consumer Thread ต้องไม่เคยทำ Synchronous External Call ออกแบบ Asynchronous Handoff Patterns เช่น Redis Queues กับ Separate Worker Pools ตั้งแต่แรก Consumer Thread ทำหน้าที่แค่ Consume และ Hand Off เท่านั้น ไม่มากกว่านั้น
สิ่งที่เห็นได้ชัดจากกรณีศึกษานี้คือว่า Engineering Culture ที่แข็งแกร่งไม่ได้เกิดจากมาตรฐานที่ถูกกำหนดลงมาจากด้านบน แต่เกิดจากทีมหน้างานที่ผ่านความเจ็บปวดใน Production แล้วนำความรู้นั้นกลับมา Refine Architecture ใหม่จนกระทั่งระบบทำงานได้อย่างมั่นคง — และเมื่อ Insight เชิงลึกเหล่านี้สะสมพอสมควร มันจะค่อยๆ ส่งผลกระทบเชิงบวกกลับไปปรับปรุงมาตรฐานระดับองค์กร ทั้งในด้าน Architecture Guideline, Technology Selection Criteria และ Operational Best Practices โดยไม่ต้องมีใครสั่งการจากด้านบน
ที่ Customix เราเชื่อมั่นว่า Bottom-Up Innovation ที่เกิดจากทีมปฏิบัติการที่ลุกขึ้นมาแก้ปัญหาจริงด้วยเครื่องมือล้ำสมัยคือแหล่งพลังที่ยั่งยืนที่สุดในการสร้าง Engineering Excellence ไม่ว่าจะเป็นการออกแบบเว็บไซต์ที่ตอบโจทย์ Technical SEO, AEO และ GEO หรือการพัฒนาระบบหลังบ้านที่ต้องรับมือ Workload สูง — ทีมงานของเราพร้อมนำประสบการณ์และบทเรียนเชิงลึกเหล่านี้มาสร้างคุณค่าให้กับธุรกิจของคุณ ด้วย UX/UI Design ผ่าน Figma, Tech Stack ทันสมัย และการดูแลระบบอย่างต่อเนื่องหลังขึ้นใช้งานจริง เพื่อให้แบรนด์ของคุณน่าเชื่อถือและติดหน้าแรก Google ได้ง่ายขึ้น
ระบบที่ทำงานได้ดีที่สุดใน Production ไม่ใช่ระบบที่ Commit ไปกับ Paradigm เดียวอย่างเต็มที่ แต่เป็นระบบที่ใช้ Event-Driven Patterns อย่างมีวิจารณญาณ — พร้อมความตระหนักชัดเจนในจุดที่แบบจำลองนั้นแตก — และนั่นคือทัศนวิสัยที่ทีมหน้างานทุกคนควรถือครองไว้
แหล่งข้อมูลอ้างอิง
อ่านบทความต้นฉบับจากแหล่งข่าว: https://www.infoq.com/articles/tradeoffs-event-driven-design/?utm_campaign=infoq_content&utm_source=infoq&utm_medium=feed&utm_term=Architecture+%26+Design
สนใจบริการของ Customix?
ปรึกษาทีมผู้เชี่ยวชาญของเราได้ฟรี ไม่มีค่าใช้จ่าย