Event-Driven Architecture ในระบบ Real-Time: สิ่งที่ Architecture Diagram ไม่เคยบอกคุณ และทำไมทีมหน้างานต้องเป็นผู้บุกเบิกการเปลี่ยนแปลง
บทนำ: เมื่อ Async Pipeline ทำลาย Real-Time Contract
Event-Driven Architecture (EDA) กลายเป็นหัวใจหลักของการสร้างระบบ Distributed Systems สมัยใหม่ ด้วยสัญญาอันแสนดึงดูด: loose coupling, independent scalability, fault isolation และความสามารถในการรับมือ Throughput มหาศาลโดยไม่ต้องพึ่งพา Synchronous Dependencies สำหรับแพลตฟอร์ม Real-Time Collaboration เช่น Contact Center, Unified Communications หรือ Video Conferencing แล้ว คุณสมบัติเหล่านี้ดูเหมือนจะถูกสร้างมาเพื่อระบบพวกนี้โดยเฉพาะ
แต่ในโลกของ Production Systems จริงๆ มันไม่ได้ง่ายอย่างที่ Architecture Diagram วาดไว้ ผมใช้เวลาหลายปีในการสร้างและปรับขนาด Cloud Contact Center Platform ที่รองรับมากกว่า 80,000 Busy Hour Call Completions (BHCC) บน 10,000 Agents พร้อมกัน ประมวลผลกว่า 5 ล้าน Transactions ต่อวัน เราเลือกลงทุนอย่างเต็มที่กับ Event-Driven Architecture โดยใช้ Apache Kafka เป็น Messaging Backbone หลัก ผลลัพธ์? ผสมปนเป้นในรูปแบบที่ Diagram ไม่เคยแสดงให้เห็น
นี่ไม่ใช่บทความที่โจมตี Event-Driven Design แต่อย่างใด แต่เป็นบันทึกฉบับตรงไปตรงมาเกี่ยวกับ Tradeoffs ที่ปรากฏขึ้นเฉพาะใน Production — โดยเฉพาะในระบบที่ Real-Time Responsiveness ไม่ใช่ Nice-to-Have แต่เป็น Core Product Requirement และที่สำคัญที่สุดคือ ทีมหน้างานที่ลุกขึ้นมาแก้ปัญหาเหล่านี้ด้วยมือของตัวเอง คือกุญแจที่ผลักดันให้มาตรฐานระดับองค์กรต้องเปลี่ยนแปลง
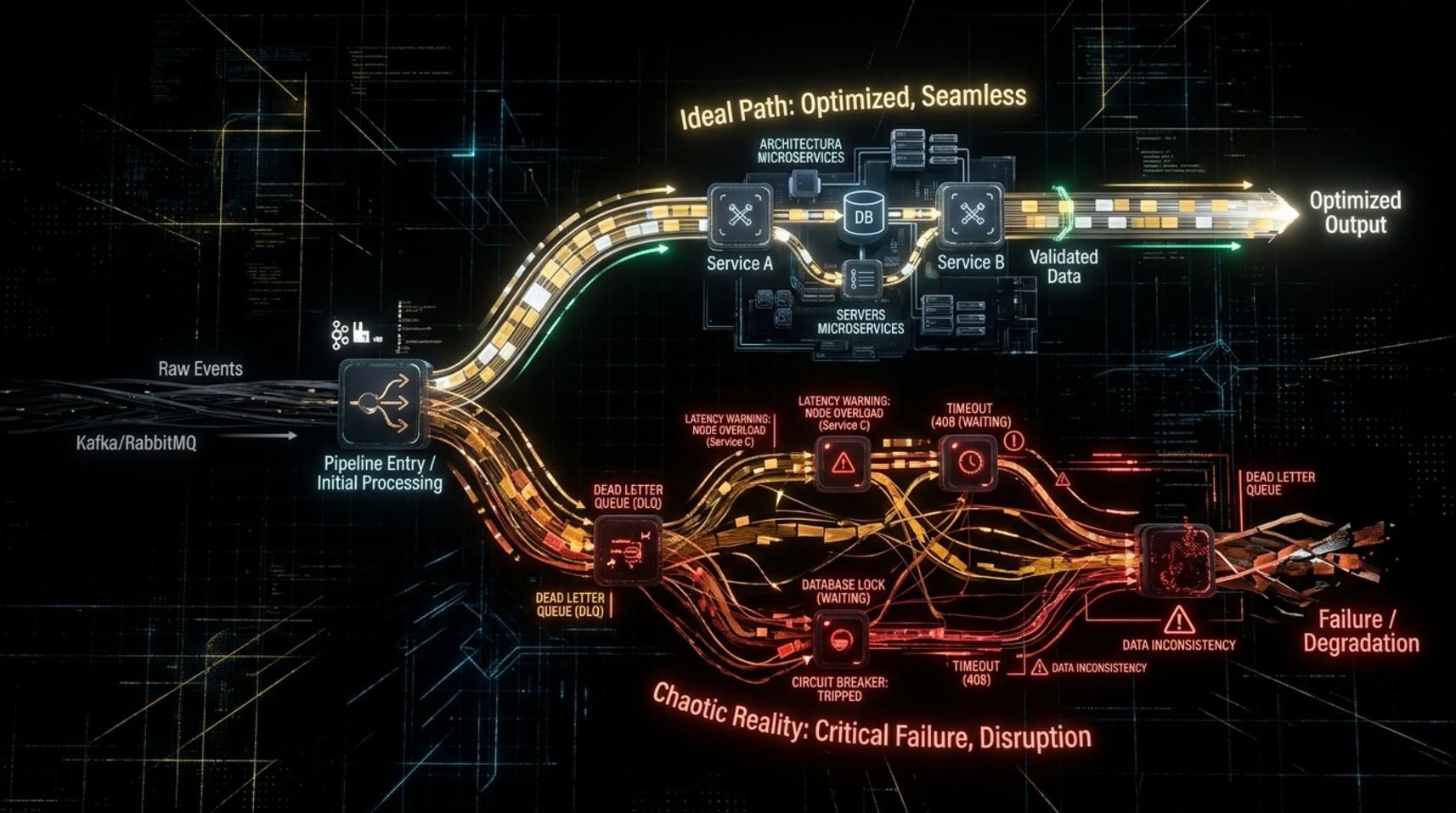
Midjourney Prompt: A dark-mode technical architecture diagram comparing ideal vs reality of event-driven microservices pipeline, left side shows clean async event flow between UI, gRPC, routing engine, agent state service, presence service and notification service with perfect arrows, right side shows the same pipeline but with red latency indicators accumulating at each hop showing 2-3 second total delay, warning symbols at bottleneck points, professional engineering blueprint style, clean typography, dark navy background with cyan and orange accent colors, isometric 3D perspective, ultra detailed, 8k quality --ar 16:9 --v 6
พิจารณาสถานการณ์จริง: เมื่อ Agent กด Outbound Call ผ่าน UI ระบบต้องสะท้อนสถานะภายในไม่กี่มิลลิวินาที ไม่ใช่ไม่กี่วินาที เมื่อ Supervisor ดู Team Dashboard ข้อมูล Presence ที่ล้าสมัยไม่ใช่เรื่องเล็กน้อย มันส่งผลต่อ Workforce Management Decisions แบบ Real-Time โดยตรง แต่ Kafka Message แต่ละข้อความที่ Publish, Consume และ Process จะเพิ่ม Latency ที่แต่ละ Hop เราพบว่า Agent กด Outbound Call แล้ว UI ใช้เวลา 2-3 วินาทีกว่าจะแสดงสถานะใหม่ ภายใต้ Peak Load บางครั้ง Inbound Call Answer Event ก็ไม่ทัน Propagate ก่อน Timeout จาก Source ด้านต้นสาย
ระบบทำงานถูกต้องตาม Technical Spec ทุกอย่าง แต่ Async Pipeline ละเมิด Real-Time Contract ที่ผลิตภัณฑ์ต้องการ — นี่คือจุดที่ทีมหน้างานต้องเริ่มตั้งคำถามกับ Architecture เดิมๆ และค้นหา Pattern ใหม่ที่ล้ำลึกกว่าเดิม สิ่งนี้เป็นตัวอย่างชัดเจนของ Grassroots Innovation ที่เกิดจาก Developer และ Architect ที่เผชิญกับปัญหาจริงในระดับ Production ไม่ใช่จากผู้บริหารที่นั่งอยู่ใน Meeting Room
3 ยุคของ State Management: จาก Cache Mismatch สู่ Redis-Backed Resilience
หนึ่งใน Benefits ที่เห็นได้ชัดของ EDA คือการที่แต่ละ Microservice ดูแล State ของตัวเอง ทำให้ไม่ต้องใช้ Shared Database และลด Tight Coupling แต่ในระบบ Real-Time Collaboration แนวทางนี้สร้างปัญหาที่ละเอียดอ่อนและอันตราย: Cache Mismatch ระหว่าง Service Instances
ในระบบของเรา แต่ละ Microservice ดูแล Local In-Memory Cache ที่สร้างจาก Kafka Events ภายใต้สภาวะปกติ ทุก Instance จะ Consume Event Stream เดียวกันและรักษา State ที่สม่ำเสมอ แต่ภายใต้ Edge Conditions เช่น Network Partitions, Consumer Lag และ Partial Restarts ต่าง Instance จะ Diverge ออกจากกัน ผลลัพธ์ที่ได้ไม่ใช่ Error หรือ Exception แต่เป็น Silent Incorrectness: Work Cards สำหรับ Voice และ Chat Engagements จะติดอยู่บน Agent UI โดยสะท้อน State ที่ไม่ตรงกับความเป็นจริงอีกต่อไป ในบางกรณี Work Cards ติดค้างมากกว่า 24 ชั่วโมงกว่าจะถูกค้นพบและแก้ไข
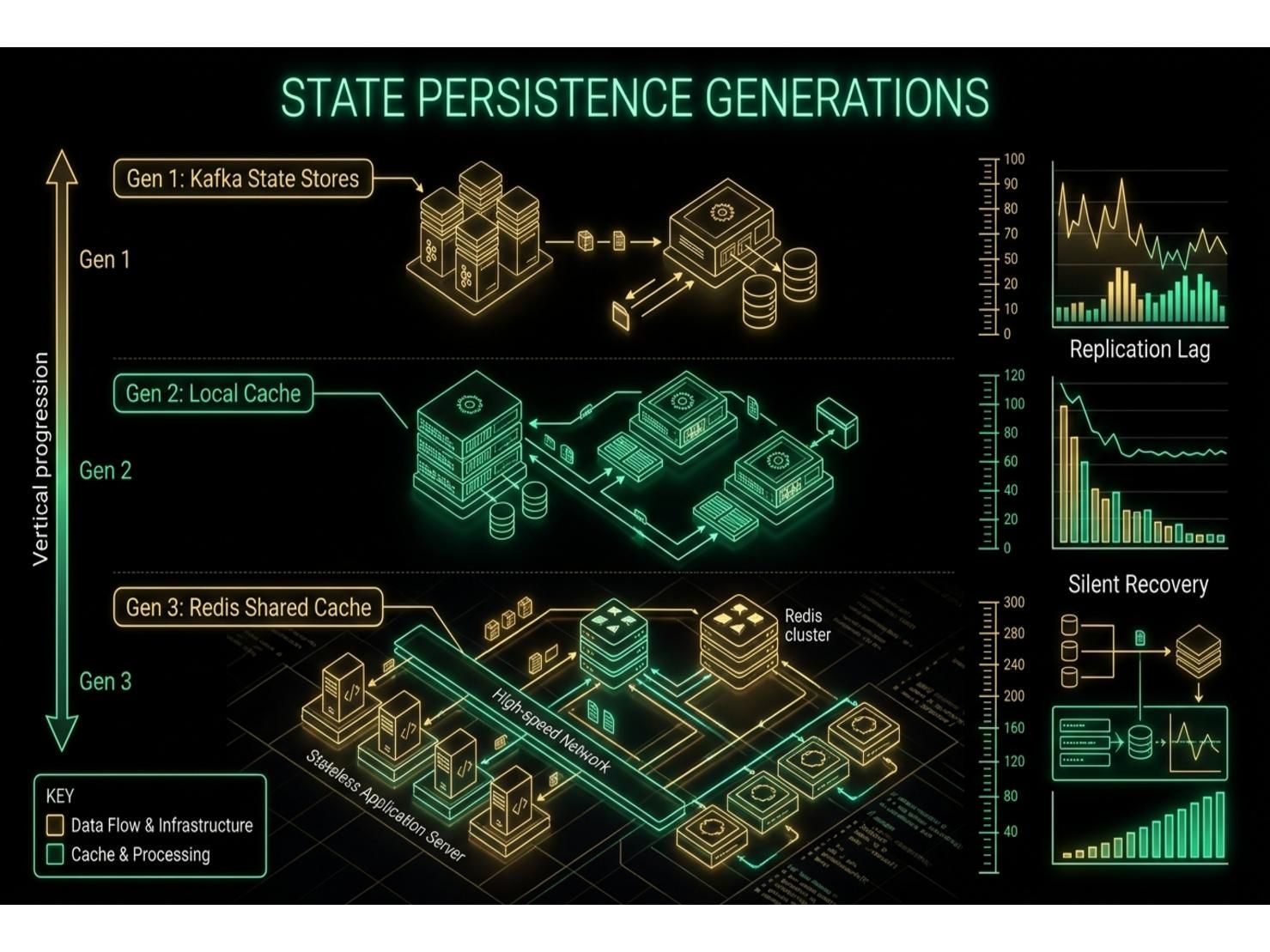
นี่คือช่วงเวลาที่ทีมหน้างานตัดสินใจขยับขั้น State Management ขึ้นอีกระดับ โดยผ่านการ Evolve ผ่าน 3 Generation ที่แต่ละ Generation แก้ปัญหาของ Generation ก่อนหน้าแต่ก็สร้างปัญหาใหม่ขึ้นมาเอง
Generation 1: Kafka Global State Stores — ใช้ Kafka Streams Global State Stores ที่ Replicate ข้อมูล Topic ไปยังทุก Pod ให้ทุก Instance มีสำเนา State แบบเต็มอยู่ในเครื่องเอง ดูเหมือนเหมาะสม แต่ Global State Stores Replicate แบบ Asynchronous ผ่าน Kafka Changelog Topics ภายใต้ Load จะเกิด Replication Lag ที่วัดผลได้ระหว่าง Pods ทำให้ Pod A และ Pod B ถือเวอร์ชัน State ของ Agent คนเดียวกันไม่ตรงกัน ท้ายที่สุด Routing Decisions จาก Pod A จะขัดแย้งกับ Pod B
Generation 2: Local In-Memory Cache via Kafka Replay — ละทิ้ง Global State Stores ทั้งหมด ให้แต่ละ Pod สร้าง Local In-Memory Cache จาก Kafka Event Stream เอง แต่ละ Event มี Header Flag (CREATED, UPDATED, DELETED) และ Pods ดูแล State ของตัวเองอย่างอิสระ ดูเหมือนแก้ปัญหา Consistency แล้วจริงๆ แต่กลับเกิด Startup Latency ที่รุนแรง: Pod ตัวใหม่ต้อง Replay ทั้ง Event Backlog กว่าจะ Rebuild Cache เสร็จ ในระบบของเราใช้เวลาประมาณ 5 นาทีต่อ Pod — ซึ่งทำให้ Kubernetes HPA Autoscaler ถูก Disabled เพราะ Pod ใหม่ที่ Trigger จาก Load Spike จะไม่พร้อมใช้งานเป็นเวลา 5 นาที นอกจากนี้ยังเกิด Cache Mismatch Problem เดิมอีกด้วย
Generation 3: Redis Shared Cache with Resilience Layer — สถาปัตยกรรมสุดท้ายเปลี่ยน Local Caches ทั้งหมดเป็น Redis ทำหน้าที่เป็น Authoritative Shared State Store Kafka Events อัปเดต Redis ทุก Pods อ่านจาก Redis โดยตรง ผลลัพธ์ Startup Delay ลดลง 60% และ Pods เริ่มต้นจาก Redis แทนที่จะ Replay Kafka Events แต่การนำ Redis เข้ามาเป็น Critical Path Dependency ต้องมี Resilience Strategy ที่ซับซ้อน: Silent Recovery Thread ที่ทำงานเบื้องหลัง — ถ้า Redis ไม่พร้อมใช้งาน Background Thread จะ Rebuild Redis Cache จาก Kafka Event Stream แบบเงียบๆ โดยไม่ Block Pod จาก Serving Traffic Pod จะเริ่มต้นด้วย Degraded State แล้ว Gradually Improve เมื่อ Recovery Thread Populate Redis เต็ม
Midjourney Prompt: A horizontal infographic comparing three generations of state management evolution in distributed systems, left section labeled Gen 1 shows Kafka Global State Stores with visible replication lag arrows between pods shown as red dashed lines, middle section labeled Gen 2 shows local in-memory caches with a 5-minute replay timer icon and divergence warning, right section labeled Gen 3 shows all pods connected to a single Redis cluster with green checkmarks and a recovery thread icon, clean modern data visualization style, gradient background from blue to teal to orange representing evolution, white labels and annotations, professional tech presentation quality --ar 16:9 --v 6
บทเรียนสำคัญ: State Management ใน Event-Driven Systems ไม่ใช่ Solved Problem แต่เป็นชุดของ Tradeoffs ที่เปิดเผยตัวเองเฉพาะภายใต้ Production Load Global State Stores สร้าง Synchronization Latency Local Caches สร้าง Startup Delays และ Divergence Shared Caches สร้าง Availability Dependencies กุญแจคือการออกแบบเพื่อรับมือทั้ง 3 Failure Modes ตั้งแต่แรก: ใช้ Redis สำหรับ Shared Authoritative State, Snapshot Initialization สำหรับ Startup Speed และ Background Recovery Thread สำหรับ Resilience อย่าค้นพบ Requirements เหล่านี้ทีละ Production Incident
และนี่คือจุดสำคัญของ Bottom-Up Drive: ไม่ใช่ CTO หรือ Enterprise Architect ที่นั่งอยู่ในสำนักงานใหญ่ที่ออกแบบ Redis Pattern นี้ แต่เป็นทีม Developers และ Solution Architects ที่เผชิญกับ Production Incidents จริงๆ ตรงหน้า และต้องบุกเบิกหาทางออกด้วยตัวเอง Pattern ที่ได้มาจาก Grassroots Innovation เหล่านี้ ภายหลังกลายเป็น Best Practice ที่ถูกนำขึ้นไปเป็นมาตรฐานระดับองค์กร เพราะมันถูกพิสูจน์แล้วในสนามจริง
Partition Limits, Deduplication Tax และ Cascading Failures: 3 มิติของ Tradeoffs ที่ซ่อนอยู่
เมื่อเราลงลึกไปอีก จะพบว่า Tradeoffs ของ EDA ไม่ได้จำกัดแค่เรื่อง State Management แต่ขยายไปถึง 3 มิติที่แยกกันไม่ออก และแต่ละมิติก็ต้องการทีมหน้างานที่มีความเชี่ยวชาญเพื่อเปิดเผยและแก้ไข
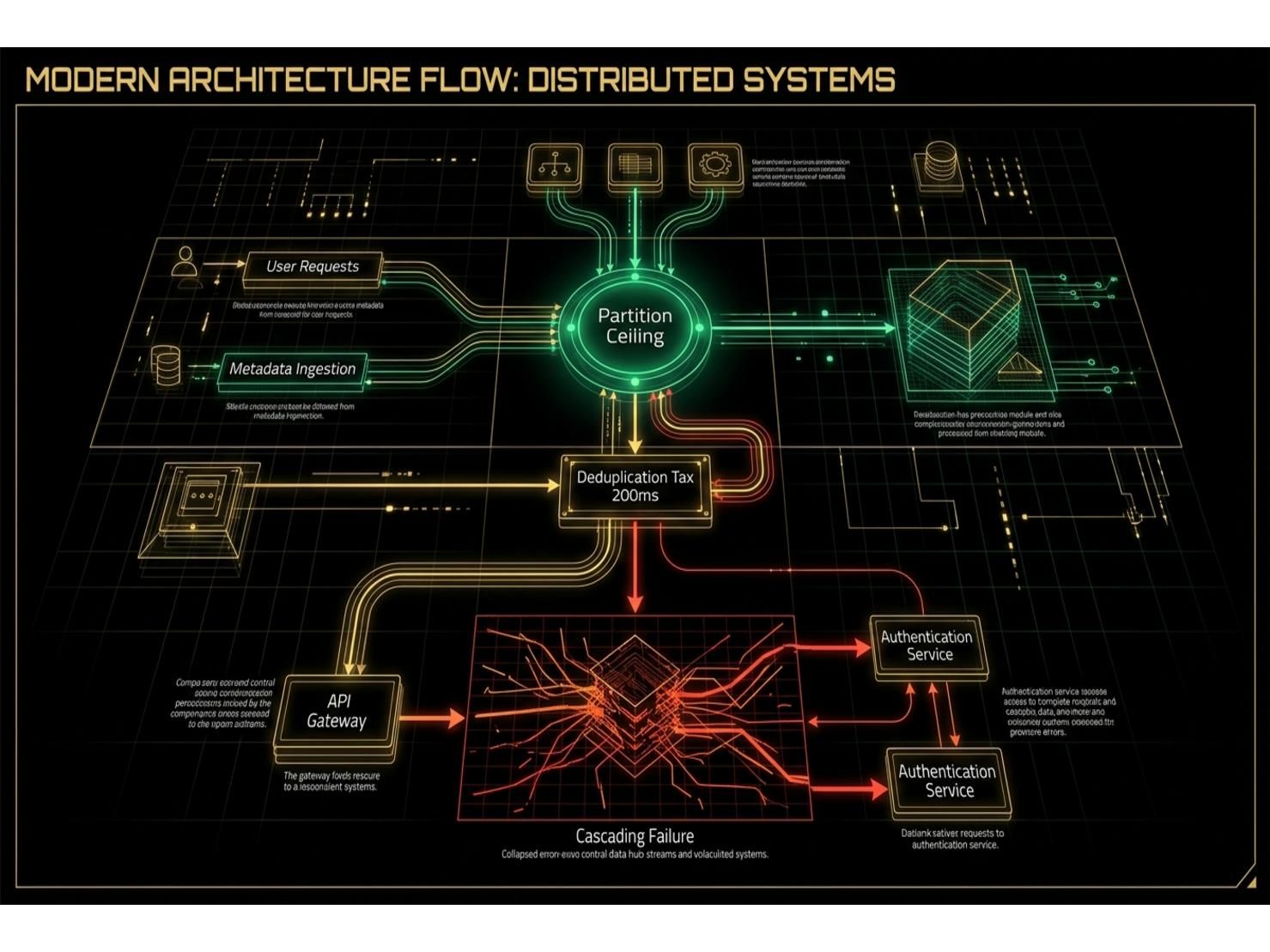
มิติแรก: Partition Limits — The Hidden Ceiling on Horizontal Scaling แบบนี้ Kafka Scalability Model บนกระดาษดูสวยงาม: เพิ่ม Partition เพิ่ม Consumer แล้ว Scale Linearly แต่ในระบบจริงที่หลาย Services แชร์ Topics เรามี Topics หลัก 12 Partitions, กลาง 6 Partitions และต่ำ 3 Partitions ปัญหาคือ Consumer Group Model กำหนดให้จำนวน Active Consumers ต่อ Topic เท่ากับจำนวน Partitions ถ้า Deploy Consumer Pods มากกว่า Partitions Pods ที่เกินจะนั่งเฉยๆ กิน Memory และ Compute โดยไม่มีส่วนร่วมกับ Throughput และการเพิ่ม Partitions บน Live Kafka Topic จะ Trigger Consumer Group Rebalancing ซึ่งระหว่าง Rebalancing Consumer Processing จะ Pause — ใน Contact Center นั้น Processing Pause ใดๆ ก็มีนัยสำคัญต่อการดำเนินงาน ทำให้เราถูก Lock-in กับ Partition Count ที่ตั้งไว้ตั้งแต่แรก Deploy
มิติที่สอง: Deduplication Tax — Cross-Cluster Event Propagation แพลตฟอร์มของเราครอบคลุม 2 Azure Kubernetes Service Clusters คือ UI Framework ในอันหนึ่ง และ Backend Routing Core ในอีกอันหนึ่ง พร้อม Voice Switch บน Google Cloud Platform แยกต่างหาก Topology นี้สร้าง Deduplication Problem ที่กลายเป็นหนึ่งใน Latency Source ที่สำคัญที่สุด เนื่องจากทุก Backend gRPC Pod Subscribe Channel เดียวกัน ทุก Pod จะได้รับทุก UI Message พร้อมกัน โซลูชันแรกใช้ Kafka เป็น Deduplication Mechanism เอง แต่ก็สร้าง Compounding Latency Problem: Kafka Consumer Default Polling Interval คือ 100ms ทำให้ทุก Event เกิด Latency อย่างน้อย 100ms ต่อ Kafka Hop และ Deduplication Pattern เพิ่ม 2 Full Kafka Hops ต่อทุก UI Interaction รวมกลายเป็น 200ms Latency ขั้นต่ำที่หลีกเลี่ยงไม่ได้ก่อน Downstream Services จะเห็น Event ใดๆ เลย
ท้ายที่สุดเราเปลี่ยนจาก Kafka-based Deduplication มาเป็น Redis First-Write-Wins Pattern: Pod แรกที่ Claim call_id Key ใน Redis สำเร็จจะเป็น Designated Processor ทันที และ Processors อื่นจะ Discard Message ทิ้งทันที แนวทางนี้ลบ Raw Topic ออกไปเลย และลด Kafka Hop หนึ่งขั้นจาก Critical Path อย่างสิ้นเชิง
มิติที่สาม: Cascading Failure — The Most Severe Production Incident Production Incident ที่รุนแรงที่สุดที่เราเคยเจอไม่ใช่ Single Failure แต่เป็น Cascade ที่ Trigger จาก REST API Call เดียวที่ช้า และ Propagate ขึ้นสู่ Upstream ผ่านทั้ง Pipeline สถานการณ์คือ Bulk Agent Provisioning: Administrator Trigger Provisioning สำหรับ 10,000 Agents จาก Admin UI ซึ่ง Publish Events ไปยัง Kafka Topic ที่มีเพียง 3 Partitions ผลคือ Consumer Lag สะสมเกิน 30 นาที Admin UI Timeout ทำงาน Bulk Provisioning ล้มเหลว แต่ไม่ใช่ Clean Failure — บาง Agents ถูก Provision บน Client Side แล้ว บางตัวยังไม่ ทิ้งระบบไว้ใน Partially Inconsistent State โดยไม่มี Automatic Reconciliation เลย
Midjourney Prompt: A dark-themed operations dashboard display showing three columns of real-time system metrics, left column shows partition ceiling graph with bar chart capping at 12 partitions marked with red warning, center column shows latency comparison between Kafka deduplication at 200ms per hop versus Redis first-write-wins at near-zero shown as green indicator, right column shows cascading failure timeline visualization starting from a single REST call expanding into 30 minute consumer lag, all displayed on monitor screens with glowing UI elements, holographic data visualizations, cyberpunk meets enterprise monitoring aesthetic, dark background with neon cyan and red accents --ar 16:9 --v 6
Remediation ต้องการ 2 สิ่ง: ประการแรก รวม 3 Provisioning Events ที่แยกกันเป็น Unified Event เดียว ลด Message Volume ลงสองในสาม และลบ Internal Join Topic ทิ้งไปเลย ประการที่สอง เปลี่ยน Synchronous REST Call เป็น Redis Queue Consumer Threads เขียน Provisioning Requests ลง Redis และ Return ทันที โดย Separate Async Worker Pool จะ Process REST Calls อย่างอิสระ Consumer Threads จะไม่ถูก Block โดย Downstream Latency อีกต่อไป ผลลัพธ์: Consumer Lag ลดประมาณ 50% Provisioning Operations กลายเป็น Restart-Safe ผ่าน Redis Queue Durability
JVM-Specific Tradeoffs: สิ่งที่ Java Architects ต้องรู้
Failure Modes ที่อธิบายข้างต้นเป็น Architectural Issues ที่ใช้ได้กับทุกภาษา แต่การสร้างระบบนี้บน Java/JVM สร้าง Constraints เพิ่มเติมที่ Java Architects ต้องจัดการอย่างชัดเจน
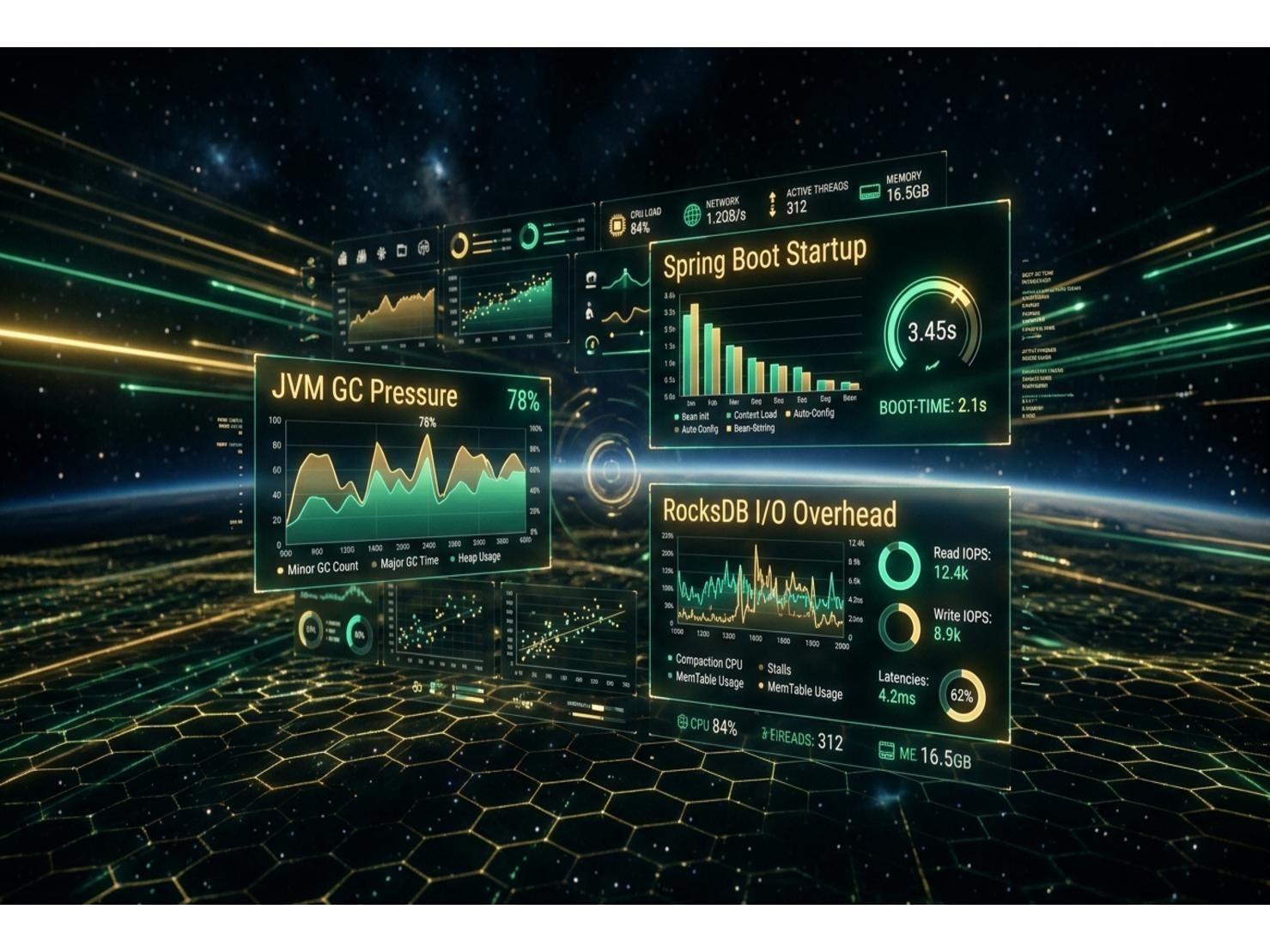
Spring Boot Startup Overhead — Application Context Initialization ของ Spring Boot ใช้เวลา Startup ประมาณ 30-45 วินาทีก่อน Kafka Consumer จะพร้อม Process Events เมื่อรวมกับ Kafka Event Replay Problem ต้นทาง Total Pod Startup Time ใน Worst Case เข้าใกล้ 6 นาที ทำให้ HPA Autoscaling Problem เลวร้ายลงกว่า Runtime ที่เบากว่ามาก การแก้ไขผ่าน Lazy Initialization (spring.main.lazy-initialization=true) และการย้ายไปใช้ Redis Snapshot Initialization ช่วยให้ Spring Boot Pod Startup ลดลงต่ำกว่า 90 วินาทีภายใต้สภาวะปกติ
GC Pressure Under High-Throughput Kafka Consumption — ภายใต้ Peak Load 80,000 BHCC และ 5 ล้าน Daily Transactions ปริมาณ Kafka Message Deserialization, Object Creation และ State Manipulation สร้าง GC Pressure อย่างมีนัยสำคัญบน JVM Heap เราพบ Stop-the-World GC Pauses ช่วง Peak ที่เป็นสาเหตุของ Consumer Lag Spikes Migration ไป JDK 17 เป็นการเปลี่ยนแปลง Single Highest-Impact ที่เราทำ G1GC Pause Target (-XX:MaxGCPauseMillis=100), Tiered Compilation (-XX:+TieredCompilation) และ Object Pooling ล้วนช่วยลด GC Pressure อย่างเป็นรูปธรรม
Kafka Streams และ RocksDB Performance Trap — หลาย Services ใช้ Kafka Streams Library สำหรับ Stateful Stream Processing แต่ Performance Profile กลับไม่เหมาะกับ Real-Time Contact Center Workloads Kafka Streams ใช้ RocksDB เป็น Embedded State Store ซึ่งเร็วสำหรับ Batch และ Near-Real-Time Workloads แต่ไม่ In-Memory Fast สำหรับ Platform ที่ Agent State Changes ต้อง Propagate ภายในหลักร้อยมิลลิวินาที ดิสก์ I/O Overhead ของ RocksDB Materialization เพิ่ม Latency ที่มองไม่เห็นใน Development แต่สำคัญมากภายใต้ Production Load โดยเฉพาะช่วงที่ Background Compaction ของ RocksDB แข่งขันกับ Foreground Read/Write Operations โดยตรง
นี่คือตัวอย่างที่สวยงามของวิวัฒนาการที่ผลักดันจากล่างสู่บน: ทีม Java Developers ที่เจอ GC Pauses และ RocksDB Latency จริงๆ ใน Production ต้องขุดลึกลงไปใน JVM Internals หา G1GC Tuning Parameters ที่เหมาะสม ทดลอง Object Pooling และท้ายท้ายต้องตัดสินใจว่า Kafka Streams + RocksDB ไม่เหมาะกับ Use Case ของตัวเอง ความรู้ที่ได้จากการเผชิญปัญหาจริงนี้ ภายหลังกลายเป็น Guideline สำหรับทีมอื่นๆ ในองค์กร ที่ไม่ต้องเจอ Production Incident เดียวกันอีก — นี่คือพลังของ Bottom-Up Knowledge Transfer
บทสรุป: 5 การตัดสินใจที่จะทำต่างจากแรก และวิสัยทัศน์ Engineering Culture ของอนาคต
มองย้อนไป มี 5 สิ่งที่จะออกแบบต่างจากแรกอย่างสิ้นเชิง:
1) ใช้ Synchronous Paths สำหรับ Latency-Sensitive Operations — Call Signaling, Agent State Transitions และ UI Notifications ควรใช้ Synchronous หรือ Low-Latency Pub/Sub เช่น WebSockets หรือ gRPC Streams แทน Kafka สำรอง Kafka ไว้สำหรับ Durable Non-Latency-Sensitive Flows: Analytics, Audit Logs และ Downstream CRM Sync
2) ใช้ Redis Shared Cache พร้อม Resilience ตั้งแต่วันแรก — อย่า Evolve ผ่าน 3 Generation ของ State Management แต่เริ่มจาก Redis เป็น Authoritative Real-Time State Store ทันที พร้อม Snapshot Initialization สำหรับ Startup Speed และ Background Recovery Thread สำหรับ Redis Outage Resilience
3) ใช้ Snapshot-First Initialization — ทุก Service ที่ต้องการ Local State ควร Initialize จาก Snapshot ไม่ใช่จาก Full Event Replay ออกแบบ Snapshot Mechanism ก่อน Deploy เข้า Production
4) ใช้ Redis-First Deduplication สำหรับ Cross-Cluster Fan-Out — Kafka-based Deduplication เพิ่ม Unavoidable Polling Latency ที่ทุก Hop Redis First-Write-Wins ควรเป็น First Choice สำหรับ Cross-Instance Deduplication
5) อย่า Block Consumer Threads เด็ดขาด — Consumer Thread ที่ต้องเรียก External Service ควรทำแบบ Asynchronous โดยเขียนไปยัง Durable Queue แล้ว Return ทันที Consumer Thread เป็นสิ่งศักดิ์สิทธิ์: หน้าที่เดียวของมันคือ Consume และ Hand Off เท่านั้น
ทุกปัญหาที่กล่าวถึงไม่ใช่เรื่องทฤษฎี ทั้งหมด Manifest ในรูปของ Production Incidents จริง: Stuck Work Cards, Agent Provisioning Timeouts, Autoscaler Paralysis, Inconsistent Call State และ UI Lag แต่สิ่งที่น่าประทับใจที่สุดคือทีมหน้างานที่ไม่ยอมแพ้ พวกเขาขุดค้น Pattern ใหม่ๆ จากการเจอปัญหาจริง ทดสอบในสนาม Production และสร้าง Knowledge Base ที่แข็งแกร่งขึ้นทุกครั้งที่ผ่าน Incident มา
นี่คือวิสัยทัศน์ที่ Customix ผู้เป็น Software House ที่ได้รับการรับรองมาตรฐาน ISO/IEC 29110 เชื่อมั่น: ไม่ว่าจะเป็นการออกแบบเว็บไซต์ที่ต้องรับมือ Traffic หนัก การพัฒนาระบบหลังบ้านที่ซับซ้อน หรือการสร้าง Architecture สำหรับ Real-Time Systems แนวคิดเรื่อง Bottom-Up Innovation และการเรียนรู้จาก Production Realities คือหัวใจของ Engineering Culture ที่แข็งแกร่ง ทีมงานที่นำโดยผู้เชี่ยวชาญที่มีประสบการณ์กว่า 5 ปี พร้อมใช้ Tech Stack สมัยใหม่อย่าง Next.js, Node.js, Redis, Jenkins และ WordPress เพื่อสร้างระบบที่ไม่ใช่แค่ Work แต่ Work อย่างยั่งยืนภายใต้ Production Load จริง
ระบบที่ทำงานได้ดีที่สุดใน Production ไม่ใช่ระบบที่ Commit เต็มรูปแบบกับ Paradigm เดียว แต่เป็นระบบที่ Apply Event-Driven Patterns อย่าง Deliberate ด้วยความตระหนักชัดเจนว่า Model นี้จะพังที่จุดไหน และมี Resilience Plan พร้อมรองรับอยู่เสมอ
![ภาพปิดท้ายสะท้อนวิสัยทัศน์ Engineering Culture: ทีม Engineers กำลังทำงานร่วมกันบน Whiteboard ที่เต็มไปด้วย Architecture Diagrams และ Production Metrics แสดงการเติบโตจาก Incident Response สู่ Proactive Design พร้อม Redis Cluster และ Kafka Streams ในพื้นหลัง เปรียบดั่งทีม Grassroots ที่กำลังปลูกฐานรากแห่ง Engineering Excellence สำหรับองค์กร [🌟 พิกัดภาพปิดท้าย]](https://cms.dev.customix.co/uploads/content4_1782986673657_4b86455769.jpg)
Midjourney Prompt: A cinematic wide shot of a modern tech team collaborating around a large illuminated whiteboard filled with architecture diagrams and production metrics graphs, the team looks determined and focused, background shows abstract visualization of Redis clusters and Kafka streams flowing like digital rivers, warm lighting with cool blue tech glow accents, represents engineering culture of bottom-up innovation and growth from incident response to proactive design, photorealistic corporate photography style, shallow depth of field, professional quality --ar 16:9 --v 6
แหล่งข้อมูลอ้างอิง
อ่านบทความต้นฉบับจากแหล่งข่าว: https://www.infoq.com/articles/tradeoffs-event-driven-design/?utm_campaign=infoq_content&utm_source=infoq&utm_medium=feed&utm_term=Architecture+%26+Design
สนใจบริการของ Customix?
ปรึกษาทีมผู้เชี่ยวชาญของเราได้ฟรี ไม่มีค่าใช้จ่าย